Everyone Has an AI Strategy. Almost Nobody Has the Infrastructure to Back It Up.
The boardroom consensus is clear: AI will transform enterprise operations.
The analyst reports agree.
The headlines agree.
The venture rounds agree.
And yet, inside most organizations, something uncomfortable is happening.
- The pilots are stalling
- The copilots are hallucinating
- The agents are failing at step three
The demos look extraordinary.
Production deployments don’t.
This is the AI Adoption Paradox — and it’s not a model problem.
It’s an infrastructure failure.
The Model Is Not the Problem
Most enterprise AI conversations focus on one thing: model capability.
“The next model will fix this.”
It won’t.
Because the bottleneck isn’t intelligence.
It’s context.
When an AI system is asked:
“Which contracts are up for renewal this quarter?”
It doesn’t fail because the model is weak.
It fails because the answer is buried inside:
- PDFs
- Email threads
- Scattered folders
- Disconnected SaaS tools
The information exists — but not in a form machines can reliably use.
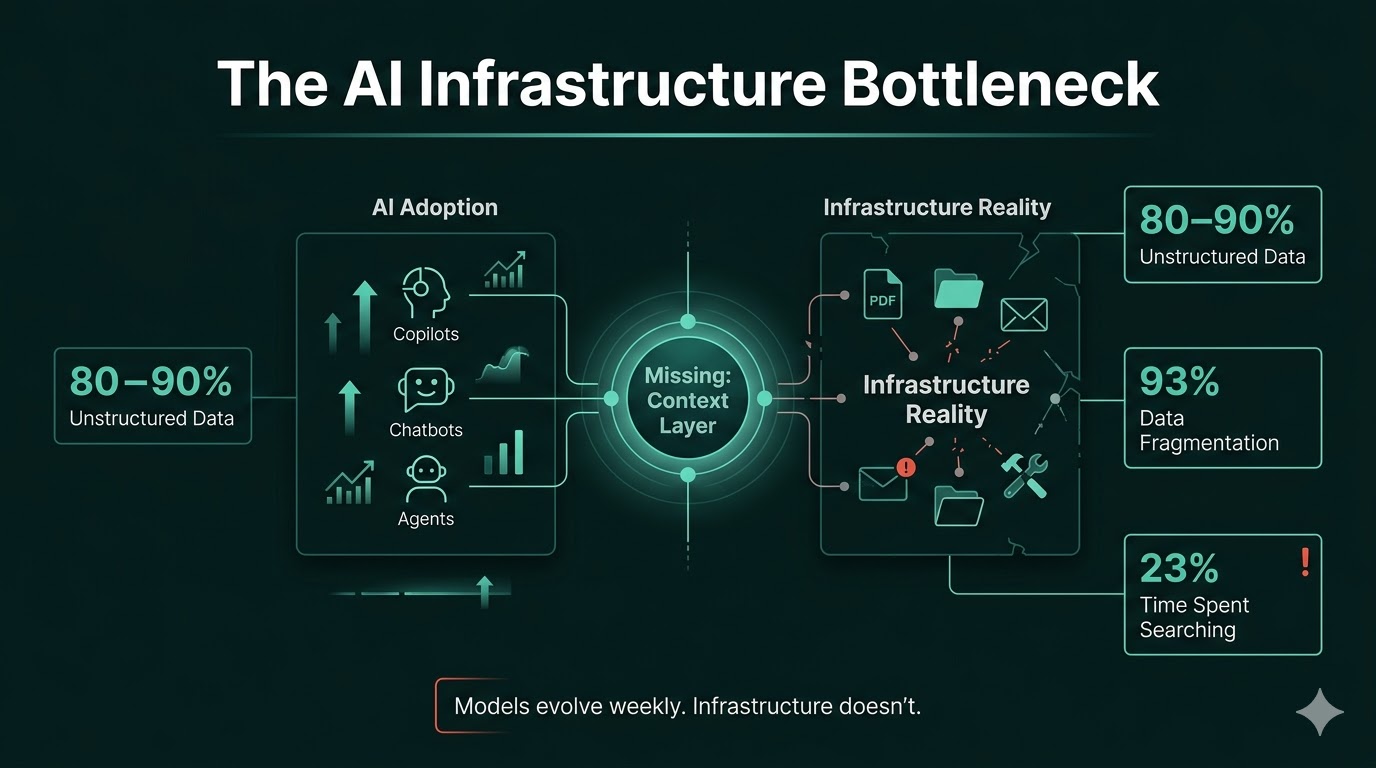
Today, 80–90% of enterprise knowledge is unstructured.
It was never designed to be machine-readable.
It was designed to be stored.
And that’s the problem.
You cannot build a reliable AI system on top of an unreliable knowledge foundation.
The Invisible Layer: Enterprise Knowledge "Dark Matter"
Over the last 20 years, companies built powerful infrastructure for structured data.
- Data warehouses
- Analytics pipelines
- Real-time dashboards
Structured data is, for the most part, solved.
But it only represents 10–20% of what organizations actually know.
The rest lives in what can be described as:
The dark matter of enterprise knowledge
- Contracts
- Decks
- Internal memos
- Legal documents
- Financial reports
- Historical decisions
This information:
- Exists
- Accumulates
- Contains critical context
But is effectively invisible to machines.
Not because it's inaccessible —
but because it’s not structured for reasoning.
Why Current Tools Will Never Solve This
Most companies assume tools like:
- Google Drive
- Dropbox
- Notion
- SharePoint
are part of the solution.
They’re not.
They were designed for:
- Storage
- Sharing
- Collaboration
Not for:
- Reasoning
- Context modeling
- Knowledge computation
They answer:
“Can a human access this file?”
But AI needs to answer:
“Can a machine understand and reason over this knowledge?”
Those are fundamentally different problems.
What a Knowledge-Native Infrastructure Looks Like
Fixing this requires a new foundational layer.
Not a better chatbot.
Not a smarter search bar.
A new system of record for knowledge itself.
This layer transforms documents into structured, computable context.
It does three critical things:
1. Entity Extraction
Identify key elements across documents:
- companies
- people
- contracts
- obligations
- deadlines
2. Relationship Modeling
Connect how those entities interact:
- who signed what
- which contracts relate to which vendors
- which approvals led to which decisions
3. Continuous Knowledge Graph
Build a live system that:
- updates as documents change
- reflects real organizational state
- enables queryable context
The Shift: From Files → Knowledge Systems
Once this layer exists, everything changes.
Instead of asking:
“Where is this document?”
You ask:
“What do we know about this?”
Instead of retrieving files,
you retrieve answers grounded in context.
Instead of static storage,
you get a living organizational memory.
Why This Changes AI Completely
When AI systems operate on structured context:
- hallucinations drop
- answers become traceable
- reasoning becomes reliable
Not because models improved —
but because the foundation did.
Better inputs → Better reasoning → Real outcomes
The Window Is Now
By 2026, 80% of enterprises will deploy generative AI.
Most will fail to unlock its full value.
Not because they lack talent.
Not because they lack ambition.
But because they’re building on top of:
Fragmented, unstructured, non-computable knowledge systems
The winners of the AI era won’t be the ones with the best models.
They’ll be the ones with the best context infrastructure.
The End of the Folder Era
The nested folder had a 40-year run.
It worked for humans.
It does not work for machines.
And in an AI-first world,
that’s no longer acceptable.
What Comes Next
A new category is emerging:
The Operating Context Layer
A system where:
- knowledge is structured
- relationships are modeled
- AI can reason reliably
This is not an upgrade to existing tools.
It’s a replacement for how organizations understand and operate on knowledge.
The question is no longer:
“Should we adopt AI?”
It’s:
“Is our knowledge infrastructure ready for AI?”
Because without that foundation,
your copilots will always be flying blind.
Yogesh is the CEO and Co-Founder of Orvyn Labs, building the AI-native Operating Context Layer for enterprise knowledge.