Most Companies Don’t Have a Data Problem. They Have a Representation Problem.
When organizations struggle with AI, the first assumption is usually:
“We don’t have enough data.”
In reality, the opposite is true.
Companies today are overwhelmed with information.
Documents, emails, reports, dashboards, presentations — knowledge is being generated at an unprecedented pace.
The real issue is not the absence of data.
It’s that the majority of this knowledge is not structured in a way machines can understand.
Where Enterprise Knowledge Actually Lives
Ask a simple question inside any company:
“Where is our knowledge stored?”
The answer is never a single system.
It’s everywhere.
- Contracts exist as PDFs in shared drives
- Decisions are buried in email threads
- Financial data is spread across spreadsheets
- Strategy lives inside slide decks
- Conversations happen across chat tools
Each of these sources contains valuable context.
But none of them are designed to work together.
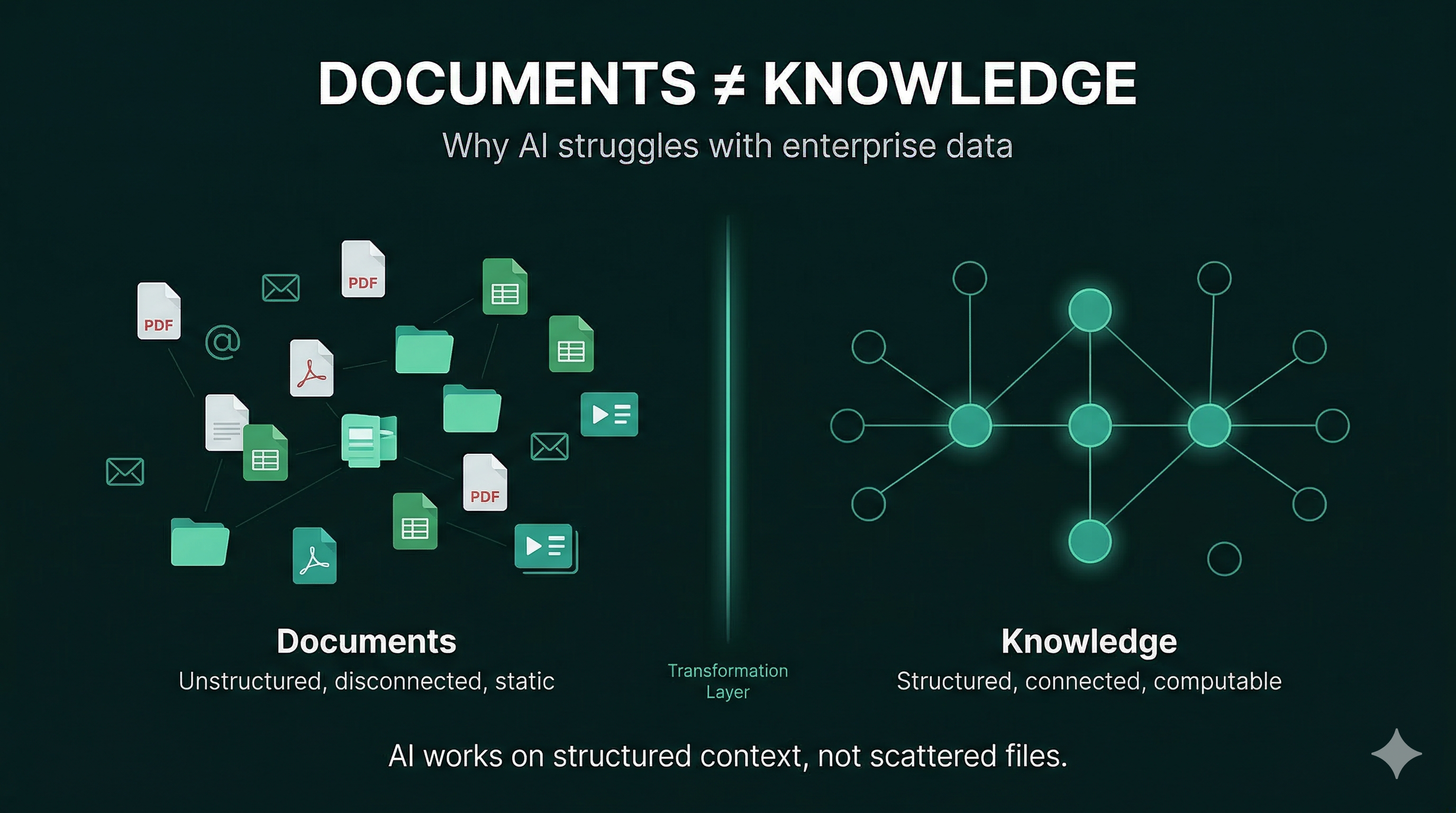
Documents Were Built for Humans — Not Machines
Documents are one of the oldest digital abstractions.
They were designed for:
- readability
- sharing
- archiving
Not for:
- computation
- reasoning
- relational understanding
A document can tell a story.
But it cannot expose structure in a way machines can reliably use.
For example:
A contract PDF may contain:
- parties involved
- obligations
- deadlines
- financial terms
But to an AI system, it’s just text — unless that structure is explicitly extracted.
Why This Breaks AI Systems
Modern AI systems require more than text.
They require context.
When an AI agent is asked:
“Which contracts are up for renewal this quarter?”
It needs to understand:
- what a contract is
- who the parties are
- when it expires
- how it relates to other agreements
If this information is buried across multiple documents,
the AI is forced to reconstruct it on the fly.
This leads to:
- incomplete answers
- hallucinations
- inconsistent outputs
Not because the model lacks intelligence,
but because the input lacks structure.
The Core Insight: Documents Are Not a Data Model
This is the fundamental shift most organizations have not yet made:
Documents are not a reliable data structure for machines.
They are containers of information — not representations of knowledge.
As long as enterprise systems rely on documents as the primary unit of knowledge,
AI will remain limited in its ability to reason and automate.
What Needs to Change
To make AI truly effective, organizations need to move beyond documents as the core layer.
This requires transforming information into:
- structured entities
- explicit relationships
- queryable context
Instead of storing knowledge as files,
it must be represented as a system of interconnected information.
From Documents to Knowledge Systems
This shift can be summarized simply:
Documents → Data → Knowledge
- Documents store information
- Data structures information
- Knowledge connects and contextualizes it
AI operates effectively only at the final layer.
The Path Forward
Organizations that want to unlock AI’s full potential must rethink how they represent knowledge.
This doesn’t mean eliminating documents.
It means building a layer above them that extracts and structures the information within.
A system where:
- knowledge is no longer trapped inside files
- relationships are explicit
- context is continuously updated
The Bigger Picture
The future of enterprise software is not just about storing information.
It’s about making knowledge computable.
And that requires moving beyond documents as the foundation.
The question is no longer:
“Do we have enough data?”
It’s:
“Can our systems understand what we already know?”